
图论
图论
稀疏图与稠密图
概念:
有很少条边或弧的图称为稀疏图,反之称为稠密图。 这里稀疏和稠密是模糊的概念,都是相对而言的。目前为止还没有给出一个量化的定义。比方说一个有 100 个顶点、200 条边的图,与 100 个顶点组成的完全图相比,他的边很少,也就是所谓的稀疏了。
用n表示图中顶点数目,用e表示图中边或弧的数目
稀疏图: e < nlogn
稠密图: e > nlogn
若图中边或弧上有权,则该图称为网
稠密图用邻接矩阵存储
稀疏图用邻接表存储
原因:
邻接表只存储非零节点,而邻接矩阵则要把所有的节点信息(非零节点与零节点)都存储下来。
稀疏图的非零节点不多,所以选用邻接表效率高,如果选用稠密图就会造成很多空间的浪费,矩阵中大多数都会是零节点!稠密图的非零界点多,零节点少,选用邻接矩阵是最适合不过!
树与图的dfs
树的重心
重心定义:重心是指树中的一个结点,如果将这个点删除后,剩余各个连通块中点数的最大值最小,那么这个节点被称为树的重心。
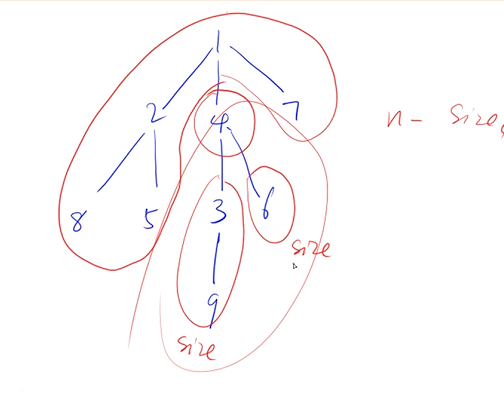
删除 1 号点,剩余各个连通块中点数的最大值最小为 4 .
思路 : 统计删除结点中(包括删除的结点 size)的每颗子树中的最大结点数 , n - size 统计已删除结点的父结点中结点数
//返回以u为根的子树中节点的个数,包括u节点 |
树与图的bfs
图中点的层次
走迷宫找 1 号点到 n 号点的最短距离,但是可能存在环void bfs(int u){
memset(d, -1, sizeof d);
d[1] = 0;
q.push(u);
while(q.size()){
int c = q.front();
q.pop();
for(int i = h[c]; ~ i; i = ne[i]){
int j = e[i];
if(d[j] == -1){
d[j] = d[c] + 1;
q.push(j);
}
}
}
}
最短路问题
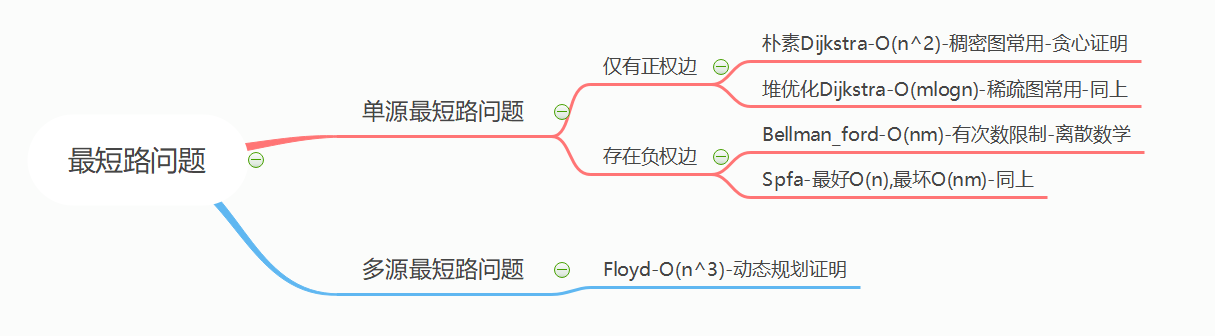
Dijkstra
迪杰斯特拉算法采用的是一种贪心的策略。
Dijkstra求最短路 I $(O(n^2))$
void Dijkstra() |
Dijkstra求最短路 II $(O(mlogn))$
算法的主要耗时的步骤是从dist 数组中选出:没有确定最短路径的节点中距离源点最近的点 t。只是找个最小值而已,没有必要每次遍历一遍dist数组。
在一组数中每次能很快的找到最小值,很容易想到使用小根堆。可以使用库中的小根堆。int dijkstra()
{
memset(dist, 0x3f, sizeof dist);//距离初始化为无穷大
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;//小根堆
heap.push({0, 1});//插入距离和节点编号
while (heap.size())
{
auto t = heap.top();//取距离源点最近的点
heap.pop();
int ver = t.second, distance = t.first;//ver:节点编号,distance:源点距离ver 的距离
if (st[ver]) continue;//如果距离已经确定,则跳过该点
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i])//更新ver所指向的节点距离
{
int j = e[i];
if (dist[j] > dist[ver] + w[i])
{
dist[j] = dist[ver] + w[i];
heap.push({dist[j], j});//距离变小,则入堆
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
bellman-ford
松弛的概念:
- 考虑节点
u以及它的邻居v,从起点跑到v有好多跑法,有的跑法经过u,有的不经过。 - 经过
u的跑法的距离就是distu + u到v的距离。 - 所谓松弛操作,就是看一看
distv和distu + u到v的距离哪个大一点。
如果前者大一点,就说明当前的不是最短路,就要赋值为后者,这就叫做松弛。
Bellman_ford 算法是求含负权图的单源最短路径的一种算法,效率较低,代码难度较小。其原理为连续进行松弛,在每次松弛时把每条边都更新一下,若在 n - 1 次松弛后还能更新,则说明图中有负环,因此无法得出结果,否则就完成。
有边数限制的最短路
为什么是dist[n] > 0x3f3f3f3f/2, 而不是dist[n] > 0x3f3f3f3f ?
5号节点距离起点的距离是无穷大,利用5号节点更新n号节点距离起点的距离,将得到$10^9−2$, 虽然小于$10^9$, 但并不存在最短路,(在边数限制在k条的条件下)。int bellman_ford() {
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < k; i++) {//k次循环 走过k条边
memcpy(back, dist, sizeof dist);
for (int j = 0; j < m; j++) {//遍历所有边
int a = e[j].a, b = e[j].b, w = e[j].w;
dist[b] = min(dist[b], back[a] + w);
//使用backup:避免给a更新后立马更新b, 这样b一次性最短路径就多了两条边出来
}
}
if (dist[n] > 0x3f3f3f3f / 2) return -1;
else return dist[n];
}
spfa
Bellman_ford 算法会遍历所有的边,但是有很多的边遍历了其实没有什么意义,我们只用遍历那些到源点距离变小的点所连接的边即可,只有当一个点的前驱结点更新了,该节点才会得到更新;因此考虑到这一点,我们将创建一个队列每一次加入距离被更新的结点。
Bellman_ford 算法里最后return -1的判断条件写的是dist[n] > 0x3f3f3f3f/2;而 spfa 算法写的是 dist[n] == 0x3f3f3f3f 其原因在于 Bellman_ford 算法会遍历所有的边,因此不管是不是和源点连通的边它都会得到更新;但是SPFA算法不一样,它相当于采用了BFS,因此遍历到的结点都是与源点连通的,因此如果你要求的 n 和源点不连通,它不会得到更新,还是保持的0x3f3f3f3f。
Bellman_ford 算法可以存在负权回路,是因为其循环的次数是有限制的因此最终不会发生死循环;但是 SPFA 算法不可以,由于用了队列来存储,只要发生了更新就会不断的入队,因此假如有负权回路请你不要用 SPFA 否则会死循环。
由于 SPFA 算法是由 Bellman_ford 算法优化而来,在最坏的情况下时间复杂度和它一样即时间复杂度为 O(nm) ,假如题目时间允许可以直接用 SPFA 算法去解 Dijkstra 算法的题目。
求负环一般使用SPFA算法,方法是用一个cnt数组记录每个点到源点的边数,一个点被更新一次就 +1,一旦有点的边数达到了 n 那就证明存在了负环。
spfa求最短路
int spfa(){ |
spfa判断负环
方法 1:统计每个点入队的次数,如果某个点入队 n 次,则说明存在负环
方法 2:统计当前每个点的最短路中所包含的边数,如果某点的最短路所包含的边数大于等于 n,则也说明存在环bool spfa(){
// 这里不需要初始化dist数组为 正无穷/初始化的原因是, 如果存在负环, 那么dist不管初始化为多少, 都会被更新
queue<int> q;
//不仅仅是1了, 因为点1可能到不了有负环的点, 因此把所有点都加入队列
for(int i=1;i<=n;i++){
q.push(i);
st[i]=true;
}
while(q.size()){
int t = q.front();
q.pop();
st[t]=false;
for(int i = head[t];i!=-1; i=ne[i]){
int j = e[i];
if(dist[j]>dist[t]+w[i]){
dist[j] = dist[t]+w[i];
cnt[j] = cnt[t]+1;
if(cnt[j]>=n){
return true;
}
if(!st[j]){
q.push(j);
st[j]=true;
}
}
}
}
return false;
}
Floyd
Floyd求最短路
d[i][k] 是 INF 但是 d[k][j]是 -2 因为 i 是到不了 k 的, 所以 k 也是到不了 j 的, 那么 i 就到不了 j .void floyd() {
for(int k = 1; k <= n; k++)
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
最小生成树问题
Prim
Dijkstra算法是更新到起始点的距离,Prim是更新到集合S的距离
Prim算法求最小生成树
bool prim(){ |
Kruskal
Kruskal算法求最小生成树
|
二分图问题
定义:图中点通过移动能分成左右两部分,左侧的点只和右侧的点相连,右侧的点只和左侧的点相连。
判定二分图
|
匈牙利算法
二分图的最大匹配
一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。//递归找可以匹配的点
bool find(int x){
// 和各个点尝试能否匹配
for(int i = h[x]; i != -1; i = ne[i]){
int b = e[i];
if(!st[b]){//打标记
st[b] = 1;
// 当前尝试点没有被匹配或者和当前尝试点匹配的那个点可以换另一个匹配
if(match[b] == 0 || find(match[b])){
// 和当前尝试点匹配在一起
match[b] = x;
return true;
}
}
}
return false;
}



